AAAI 2026 | “做题家” Code LLM,像人类一样按题型高效刷题
数据派THU
2026-01-29 17:00
文章摘要
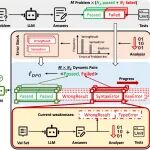
背景:在AI辅助编程技术快速发展的背景下,大语言模型生成的代码仍存在运行时错误,增加了调试成本。现有基于偏好优化的方法多依赖二元反馈信号,难以定位错误原因,且忽视了模型能力的动态变化。研究目的:针对上述缺口,提出自适应渐进式偏好优化方法(AP2O)并构建AP2O-Coder框架,旨在通过模仿人类“按题型高效刷题”的学习模式,系统化提升模型代码纠错能力。结论:AP2O-Coder框架通过“考试-分析-纠错-小测”流程,在多款主流开源模型上实现了最高3%的pass@k性能提升,同时显著降低了训练数据需求量,并展现出良好的错误抑制效果、泛化能力及跨模型类型的适配性。
本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者速来电或来函联系。